Agentic AI vs. AI Copilots in Pharma: Why Architecture Determines Impact
Your AI can answer questions about batch records. But can it investigate a deviation, correlate across systems, and draft a CAPA — autonomously, with a full audit trail?
Key Takeaways
Most pharmaceutical AI deployments are stuck at Level 3 (copilot) — reactive tools that suggest and draft but cannot reason, plan, or act. Agentic AI (Level 4) is architecturally different: goal-directed, multi-step, and autonomous within validated guardrails.
Only 6% of manufacturers currently use AI systems in production, yet an Accenture-Wharton study estimates 55% of biopharma workforce hours are impactable by AI agents — representing $180-240 billion in annual value locked behind the architecture gap.
An AI agent has five architectural components that a copilot lacks: a reasoning engine with planning capability, task decomposition, persistent memory, tool integration for cross-system execution, and guardrails that enforce GMP boundaries at every step.
The FDA itself deployed agentic AI across 70%+ of its staff in 2025. The regulator is adopting the same class of technology it is preparing to regulate — a signal that agentic architectures are the direction of travel for pharma.
In December 2025, the FDA deployed agentic AI capabilities across its own operations — a tool called Elsa, built on Anthropic’s Claude, now used by over 70% of FDA staff for pre-market reviews, inspection support, and regulatory analysis. The regulator is now using the same class of technology it is preparing to regulate under the draft EU GMP Annex 22 and its own evolving AI framework.
This whitepaper argues that most pharmaceutical companies are deploying AI at the wrong level of capability. The industry has adopted copilots — reactive, single-step tools that generate text when prompted — and declared the AI transformation underway. It is not. The operational transformation of pharmaceutical manufacturing will come from agentic AI: systems that receive goals, decompose them into tasks, reason across your data, use tools to query your systems, and execute multi-step workflows within validated guardrails. The gap between a copilot and an agent is not incremental. It is architectural.
What follows is a technical framework for understanding the four levels of AI capability in pharmaceutical manufacturing, the specific architectural components that separate an agent from a copilot, and a practical evaluation framework for CIOs preparing their organisations for the agentic era.
The difference between an AI copilot and an AI agent is not what the AI knows — it is what the AI can do. A copilot answers your questions. An agent investigates your problems.
The Copilot Plateau
Why most pharma AI investments have stalled at suggestion-level impact
The AI adoption numbers in pharmaceutical manufacturing tell a contradictory story. A Deloitte analysis found that only 6% of manufacturers currently use AI or generative AI systems in production — yet McKinsey estimates that 75-85% of pharmaceutical workflows could be enhanced by AI agents, and an Accenture-Wharton study projects $180-240 billion in annual US value from agentic AI in biopharma.
The gap between potential and reality is not a technology problem. It is an architecture problem. Most pharma companies that have deployed AI are running copilots — tools that draft deviation reports, summarise SOPs, or answer questions about regulatory guidance. These are useful. They are also fundamentally limited. A copilot waits for you to ask. It cannot investigate, correlate, or act.
6%
Of manufacturers using AI in production
Despite widespread pilot activity, production deployment remains rare (Deloitte, 2025)
55%
Of biopharma hours impactable by agents
Accenture-Wharton study estimates the majority of pharma work is agent-ready
$180-240B
Annual US value from agentic AI
Projected biopharma value from autonomous AI agents (Accenture, 2025)
Four Levels of AI Capability
A framework for understanding where your AI actually sits
Not all AI is created equal. The industry uses “AI” to describe everything from a chatbot to an autonomous agent — collapsing four fundamentally different architectures into a single term. Understanding which level your organisation operates at is the first step to understanding the gap.
Level 1: Basic LLM — stateless, no access to your data
A standalone language model that generates responses from its training data. You ask 'What are common root causes of OOS results in dissolution testing?' and get a generic answer. The model has never seen your batch records, your deviation history, or your SOPs. Every interaction starts from zero. This is a general-purpose chatbot — useful for general knowledge, useless for facility-specific quality operations.
Level 2: RAG-augmented — grounded in your documents, still reactive
Retrieval-Augmented Generation adds a document retrieval layer. Your SOPs, deviation reports, and regulatory guidance are embedded in a vector database. The system retrieves relevant content and injects it into the model's context. Now when you ask about OOS root causes, the answer references your actual investigation history. This is grounded AI — but it still only answers what you ask. If the answer requires correlating data across three systems, it cannot do that unprompted.
Level 3: AI Copilot — embedded in workflows, human does everything
The copilot wraps a RAG-augmented LLM into your existing workflow. It sits inside your quality management or batch record system, understands which screen you are on, and generates contextual suggestions: drafting a deviation report, proposing a root cause classification, summarising a batch review. Every output requires human approval before it becomes a GMP record. This is where most pharma AI deployments stop. It is faster documentation — but the same workflow, the same decisions, the same bottlenecks.
Level 4: Agentic AI — goal-directed, multi-step, autonomous
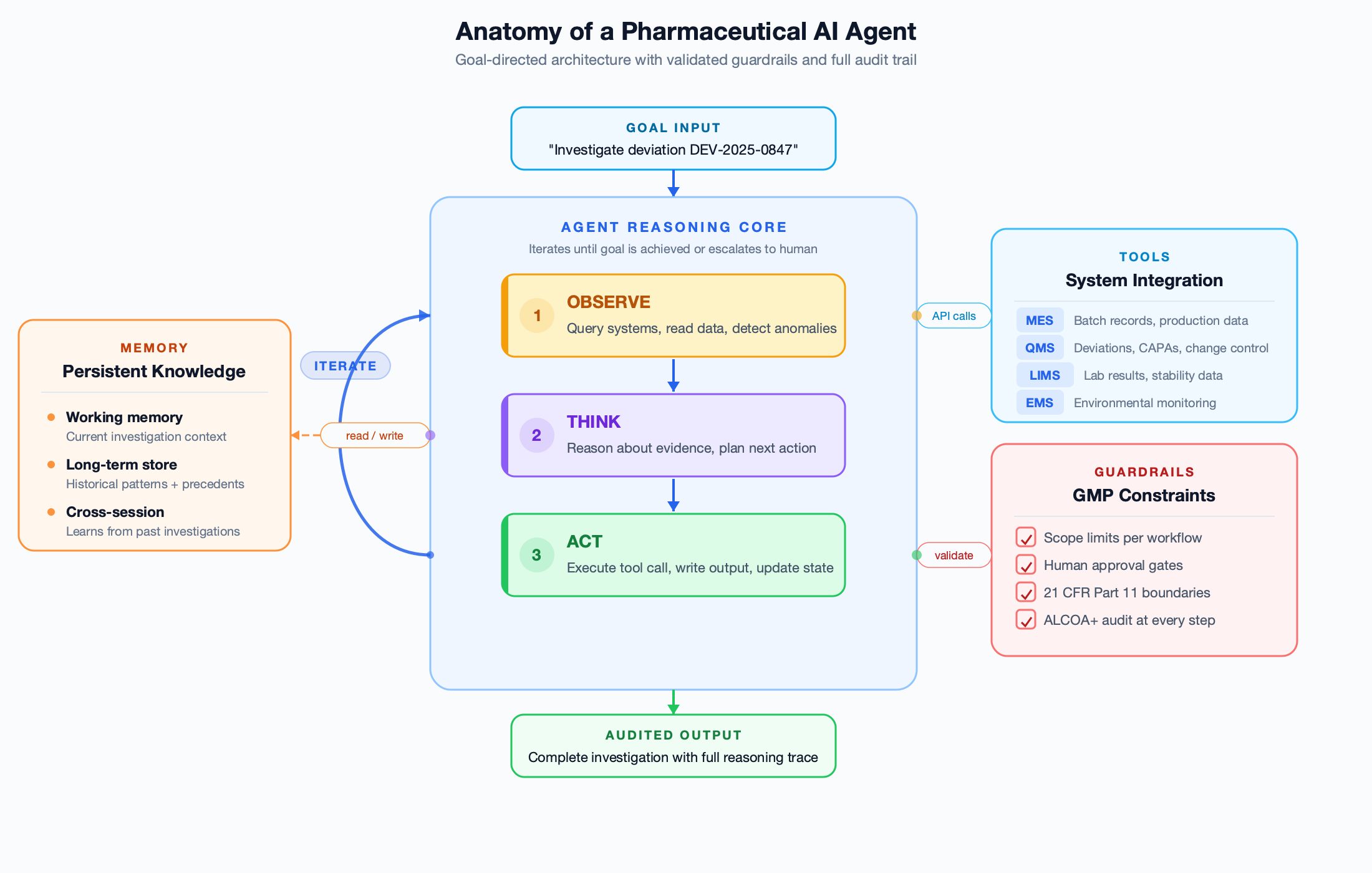
An agent receives a goal, not a prompt. 'Investigate deviation DEV-2025-0847 and assess CAPA effectiveness.' It decomposes this into sub-tasks, queries your MES for batch data, pulls environmental monitoring records, searches historical deviations for patterns, cross-references equipment maintenance logs, evaluates whether the previous CAPA prevented recurrence — and produces a complete investigation report with a full reasoning audit trail. It does not wait for you to ask each question. It reasons, plans, acts, and validates — within defined guardrails.
The question is not “are you using AI?” — every pharma company will answer yes within two years. The question is “at which level?” Organisations stuck at Level 3 will automate documentation. Organisations that reach Level 4 will transform operations.
Anatomy of a Pharma AI Agent
Five architectural components that separate an agent from a copilot
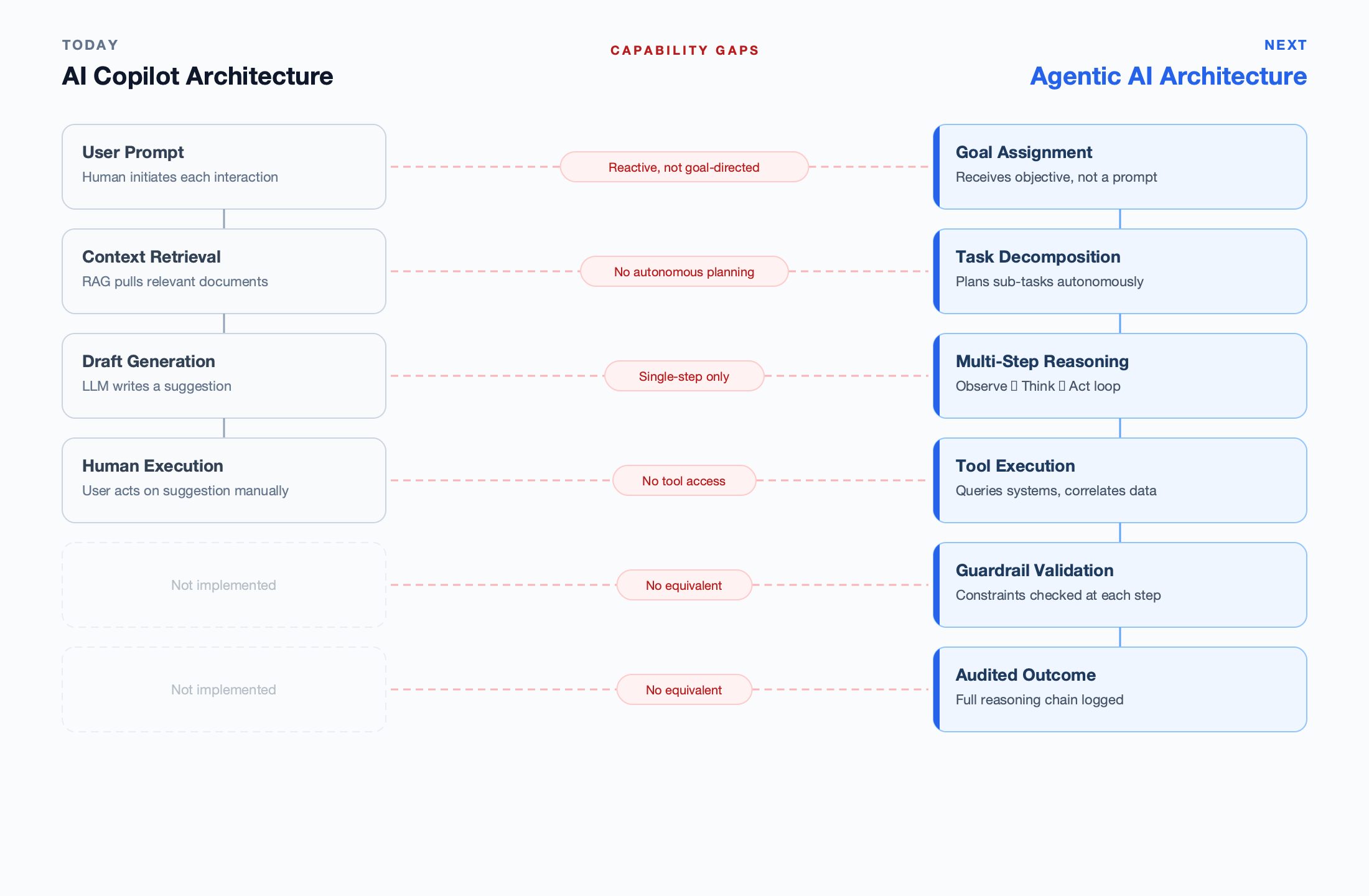
An AI agent is not a copilot with more features. It is a fundamentally different architecture. Understanding the five components that make an agent “agentic” is critical for evaluating vendor claims — and for determining whether your current AI investments can evolve or need to be replaced.
Each component below is a necessary condition. Remove any one and the system reverts to copilot-level capability.
Copilot vs. agent architecture across key dimensions
| Component | AI Copilot (Level 3) | AI Agent (Level 4) |
|---|---|---|
| Reasoning | Single inference: prompt → response | Multi-step: Observe → Think → Act loop with self-correction |
| Planning | None — responds to user requests | Decomposes goals into ordered sub-tasks autonomously |
| Memory | Session context only (resets between uses) | Working memory + long-term knowledge across investigations |
| Tool use | None — generates text only | Calls APIs, queries databases, runs calculations, writes outputs |
| Guardrails | Human reviews every output | Architectural constraints enforce GMP boundaries at every step |
| Audit trail | Logs user interactions | Logs every reasoning step, tool call, and decision with rationale |
| Trigger model | Reactive — waits for human prompt | Proactive — monitors, detects, investigates, acts |
The Observe-Think-Act Loop in Practice
How an agent investigates a deviation — compared to a copilot
The operational heartbeat of an AI agent is the Observe-Think-Act loop — a pattern first formalised by Google Research and Princeton as the ReAct framework. In benchmarks, ReAct reduced AI hallucination rates to 6% versus 14% for chain-of-thought reasoning alone, because the model grounds its reasoning in actual data from tool calls rather than generating unchecked chains of logic.
Here is how this loop operates in a pharmaceutical manufacturing context — a deviation investigation that would take a human analyst days to complete manually.
Step 1: Receive goal and decompose
Analyst opens deviation form, types 'Help me investigate DEV-2025-0847'. Copilot retrieves the deviation report and suggests a template.
Manual
Receives goal: 'Investigate DEV-2025-0847'. Autonomously decomposes into sub-tasks: retrieve report, check EMS data, identify affected batches, search historical precedents.
Seconds
Step 2: Gather evidence across systems
Analyst manually queries MES, EMS, and LIMS separately. Copies data into the investigation. Copilot can only summarise what the analyst provides.
Hours
Calls MES API for batch data, queries EMS for environmental records, searches deviation database for similar events in last 12 months — without human prompting.
Minutes
Step 3: Analyse and conclude
Analyst writes root cause analysis. Copilot can proofread or suggest formatting improvements to the text.
Days
Identifies pattern: third excursion in Room 204 in 6 months. Previous CAPAs addressed operator training; HVAC maintenance log shows 14-month gap. Drafts investigation with full evidence chain.
Minutes
Evidence from Early Adopters
Where agentic architectures are delivering measurable results
Agentic AI is not theoretical. Regulated industries — insurance, finance, and pharmaceutical manufacturing — are deploying agent architectures in production. The pattern is consistent: when organisations move from copilot-level AI to agentic architectures, the impact shifts from incremental efficiency to structural transformation.
In pharmaceutical manufacturing specifically, organisations that built their digital platforms with cross-system integration, audit trail architecture, and exception-based workflows from the start are demonstrating what agentic patterns deliver in practice.
20→1 days
Batch review cycle
Multi-site manufacturer reduced review from 20 days to 1 day through automated cross-system data aggregation and exception-based review
2,700 hrs/year
Manual effort eliminated
Previously spent on manual data entry, transcription, and cross-referencing across disconnected systems
70%+
FDA staff using agentic AI
The FDA deployed Elsa across its own operations for pre-market reviews, inspections, and compliance analysis
Agentic AI adoption across regulated industries
| Industry | Deployment | Architecture pattern | Impact |
|---|---|---|---|
| Insurance | 7-agent claim processing system | Specialised agents for coverage, fraud, payout, and audit | 80% faster claim processing |
| Finance | Agent fleets for compliance | Agents for reconciliation, KYC, and regulatory reporting | Processing reduced: days to minutes |
| Pharma | Multi-site digital platform across 30+ facilities | Cross-system batch review, deviation correlation, validation lifecycle | 95% batch review reduction |
| Regulator | FDA Elsa — agentic AI for staff | Claude-based agent in secure GovCloud | 70%+ staff adoption in first year |
Evaluating Your AI Architecture
Three capabilities that determine whether your AI is a copilot or an agent
When evaluating AI platforms — whether building internally or assessing vendors — these three architectural capabilities are the litmus test. If any one is missing, the system is a copilot, regardless of what the marketing says.
Multi-step reasoning with planning
The system must decompose goals into sub-tasks, determine execution order, and iterate when results don't meet quality criteria. Ask your vendor: 'If I give the system a goal instead of a prompt, can it plan its own investigation?' If the answer requires human prompting at each step, it is a copilot.
Cross-system tool integration
The agent must query your MES, QMS, LIMS, EMS, and document management system through defined APIs — not just search a document repository. The difference between RAG (reading documents) and tool use (querying live systems) is the difference between a research assistant and an investigator.
Validated guardrails with audit trails
Every agent action must operate within GMP-defined constraints — with the boundary between autonomous and human-required decisions architecturally enforced, not just documented. The audit trail must capture every reasoning cycle: what the agent observed, why it decided what it decided, and what it did. This is ALCOA+ applied to AI reasoning.
The organisations that will define the next era of pharmaceutical manufacturing are not the ones with the most AI pilots. They are the ones that understood the architectural difference between a copilot and an agent — and built for Level 4 from the start. Annex 22 enforcement begins in 2027. The FDA is already using agents internally. The question is no longer whether to adopt agentic AI, but whether your architecture can support it.
The publication of EU GMP Annex 22, the FDA’s own adoption of agentic AI, and the deployment evidence from regulated industries all point to the same conclusion: the copilot era in pharmaceutical manufacturing was a necessary step, but it is not the destination. Copilots helped the industry understand what AI could do with language. Agents will show what AI can do with systems.
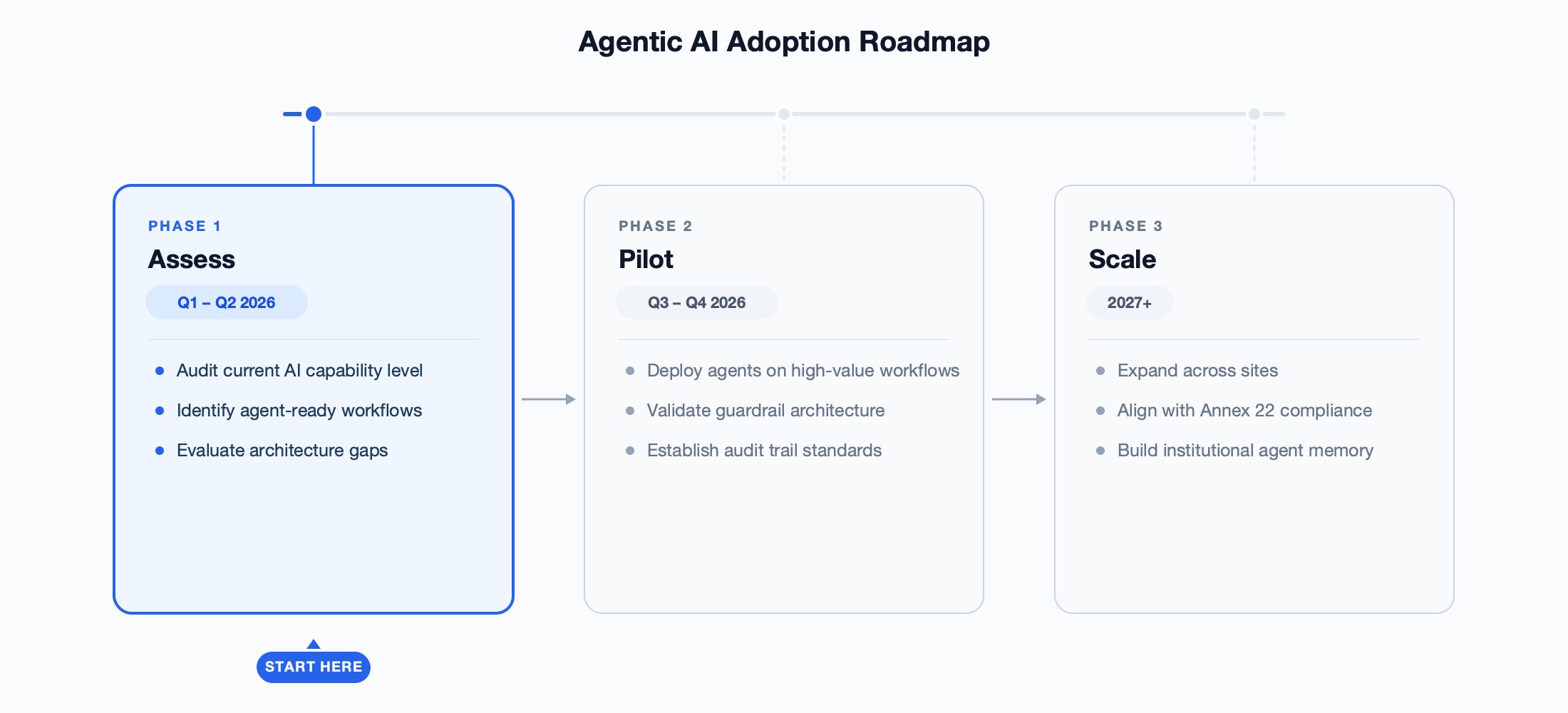
For CIOs evaluating their AI strategy, the framework is straightforward. Audit your current deployments against the four-level model. Identify which workflows are agent-ready — deviation investigation, batch review, CAPA effectiveness monitoring, cleaning validation lifecycle management. Evaluate whether your platform architecture supports the five agent components: multi-step reasoning, task decomposition, memory, tool integration, and validated guardrails. The organisations that build for Level 4 now will not just be more efficient. They will operate in a fundamentally different way — and they will be the ones setting the compliance standard that the rest of the industry follows.
Related Articles

The Quality Ontology: Why Pharma AI Needs a Knowledge Graph, Not a Data Warehouse
A technical deep-dive into the quality ontology — the connected knowledge model that enables AI agents to reason across MES, LIMS, QMS, and ERP simultaneously. How the Ontology Builder Agent constructs it, how the signal layer keeps it alive, and why this architecture is the prerequisite for every agentic use case in pharmaceutical manufacturing.

Predictive Product Quality: Why Agentic Architecture Outperforms ML Models and Dashboards
Product quality prediction requires a network of specialised AI agents — not a single ML model. How agents, skills, sub-agents, and standardised tool interfaces deliver continuous risk intelligence that annual CPV reviews structurally cannot.

Agentic Yield Intelligence: How Goal-Based AI Agents Eliminate Manufacturing Losses
Why dashboards and copilots can't solve pharma yield — and how goal-based AI agents with specialized skills autonomously prevent batch losses before they occur.
Newsletter
Stay ahead in the Industry
Regulatory updates, pharma quality insights, and AI in manufacturing — written for quality leaders, not marketers.
Please use your official work email. Personal email addresses (Gmail, Yahoo, etc.) will not receive the newsletter. No spam. Unsubscribe anytime.
Ready to see what an AI-native quality platform looks like? Leucine unifies quality management, regulatory compliance, and production operations into one intelligent system.
