Key Takeaways
Pharmaceutical manufacturing loses an estimated $50-65 billion annually to yield failures — rejected batches, rework, and sub-optimal throughput. Most of these losses share root causes with previous batches, but current systems don't cross-reference.
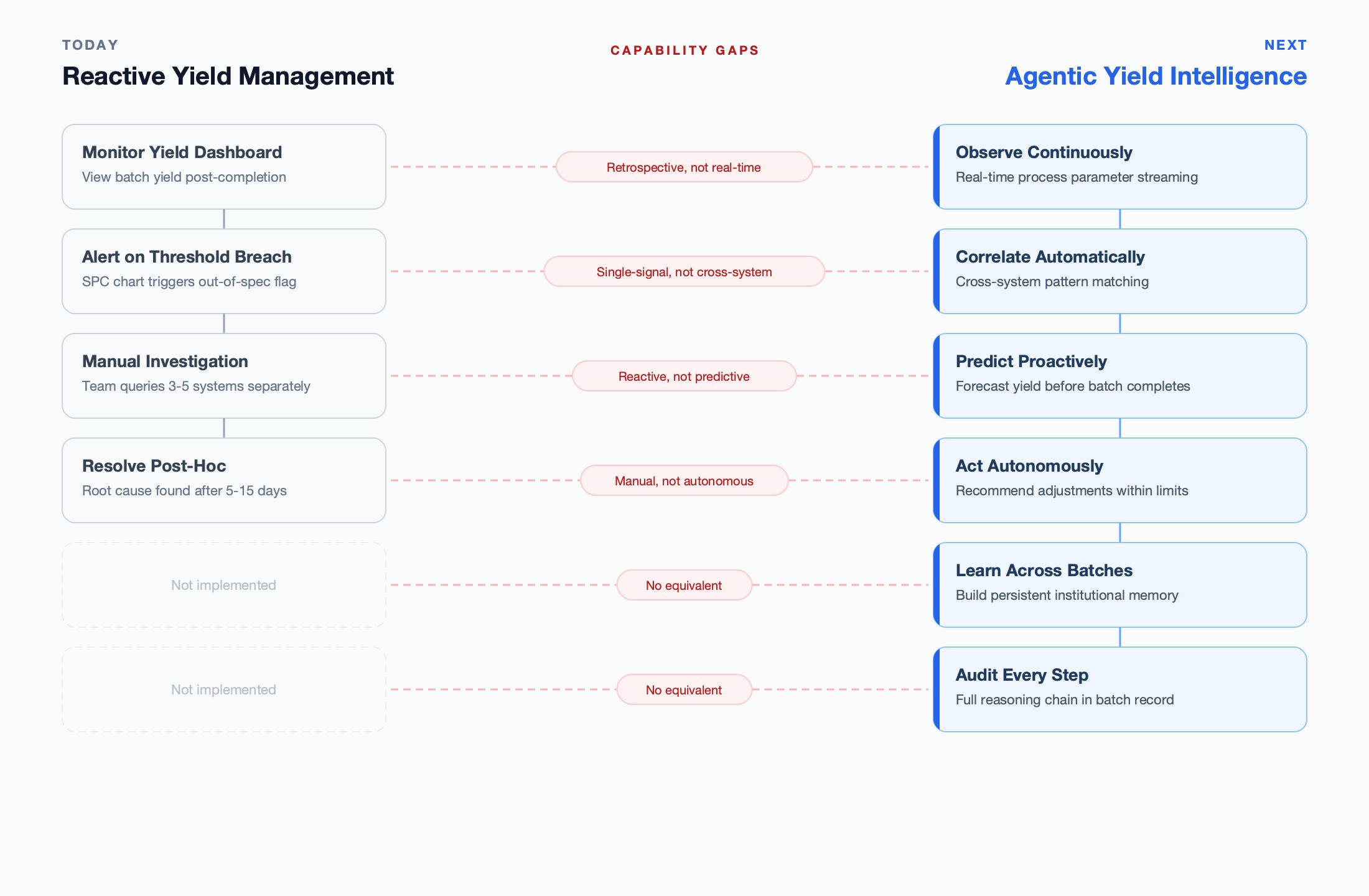
Dashboards display yield trends. Copilots suggest possible causes when asked. Neither can autonomously observe a granulation endpoint drifting, correlate it with raw material variability from a new supplier lot, and adjust downstream compression parameters — an agentic system can.
Yield intelligence requires four agent skills working in concert: yield prediction (forecasting batch outcomes from in-process data), root cause analysis (tracing failures across process, material, and environmental variables), parameter optimization (recommending adjustments within validated ranges), and cross-batch learning (building institutional memory across thousands of batches).
The integration architecture is as important as the AI: agents need real-time access to six data streams — MES batch records, process historian data, LIMS results, environmental monitoring, material COAs, and equipment maintenance logs — organized into three integration domains that most facilities keep in separate silos.
A solid oral dosage manufacturer runs 400 batches per quarter. Yield averages 94.2% — within specification, but below the 97% target established during process validation. Each percentage point of yield loss translates to roughly $180,000 in wasted API, excipients, and production time per quarter. The quality team knows yield is trending down. The manufacturing team suspects it correlates with a recent raw material supplier change. The engineering team thinks it might be a compression force calibration drift. All three teams are investigating independently — reviewing different data sets, in different systems, on different timelines.
This is the yield intelligence problem in pharmaceutical manufacturing. Not a shortage of data — most facilities generate terabytes of process data per month — but a structural inability to reason across data sources, correlate signals across batches, and act on insights before the next batch fails. The industry has spent two decades investing in data collection (PAT sensors, electronic batch records, LIMS integration) and the last three years experimenting with AI dashboards and copilots. Neither has fundamentally changed how yield losses are identified, investigated, or prevented.
This whitepaper argues that yield intelligence requires a different class of AI: goal-based agents with specialized skills that can autonomously observe process parameters in real time, reason about yield deviation patterns across historical data, and act to prevent losses — all within GMP-compliant guardrails and a full audit trail. The architecture of these agents, the skills they need, the data integrations they require, and the practical scenarios where they deliver measurable impact are the subject of what follows.
A yield dashboard tells you what happened. A copilot tells you what might have happened — if you ask the right question. An agent investigates what is happening, determines why, and recommends what to do next — autonomously, across every batch.
The Yield Gap: $50-65 Billion in Annual Manufacturing Losses
Quantifying the cost of reactive yield management
Pharmaceutical manufacturing yield losses are rarely catastrophic — they’re chronic. Batches don’t fail dramatically; they underperform incrementally. A granulation that runs 2% below target. A coating process that requires 15% more material than the theoretical calculation. A tablet press that produces 3% more rejects than its validated baseline. These small losses compound across hundreds of batches, dozens of products, and multiple facilities.
The financial impact is substantial, but the operational impact is worse: every yield deviation triggers an investigation, every investigation consumes quality and manufacturing resources, and every resolution takes days to weeks — during which the same root cause may be affecting subsequent batches.
$50-65B
Annual industry yield losses
Across rejected batches, rework, sub-optimal throughput, and investigation costs (ISPE/McKinsey estimates)
70%
Repeat root causes
Of yield deviations share underlying causes with previous batches — but are investigated independently each time
5-15 days
Average investigation cycle
Per yield deviation, involving 3-5 departments reviewing data in separate systems
Why Dashboards and Copilots Can't Solve Yield
The structural limitations of current approaches
The pharma industry’s response to yield challenges has followed a predictable technology adoption curve: first statistical process control (SPC) charts, then real-time dashboards, and most recently AI copilots that can answer natural language questions about batch data. Each generation has improved visibility — but none has changed the fundamental dynamic of reactive investigation.
Dashboards display, they don't diagnose
A real-time yield dashboard shows you that Batch 2847 is trending below target. It doesn't tell you why — or whether the same pattern preceded three previous failures. The human operator still needs to manually query multiple systems to form a hypothesis.
Copilots answer, they don't investigate
An AI copilot can analyse yield data when prompted: 'What caused the yield drop in Batch 2847?' But it only searches the context you give it. It won't autonomously check whether the API lot changed, whether humidity was anomalous, or whether the granulator blade was last maintained 20 batches ago.
Neither system crosses data boundaries
Yield root causes span MES batch records, LIMS analytical results, process historian sensor data, material management COAs, and equipment logs. Dashboards and copilots are typically connected to one or two of these systems — not all six.
Neither system acts on insights
Even when a dashboard or copilot surfaces an insight, the corrective action still requires a human to interpret the finding, draft a recommendation, route it for approval, and implement it. By the time this cycle completes, 5-10 more batches have run with the same issue.
The yield problem is not a data problem — it’s a reasoning problem. Facilities have the data. What they lack is a system that can reason across all of it, autonomously, in real time, batch after batch.
Agentic Yield Intelligence: Four Skills, One Goal
How goal-based agents reason about manufacturing yield
An agentic yield intelligence system is architecturally different from a dashboard or copilot. It receives a goal — “maximise yield for Product X within validated parameters” — and autonomously deploys specialized skills to achieve it. The agent doesn’t wait to be asked. It continuously observes, reasons, and acts across every batch, building institutional knowledge with each cycle.
Four specialized skills form the core of agentic yield intelligence, each operating within the Observe-Think-Act reasoning loop.
The four agent skills for yield intelligence — reactive vs. copilot vs. agentic approaches
| Capability | Reactive (SPC/Dashboard) | Copilot (Prompted AI) | Agentic (Goal-Based Agent) |
|---|---|---|---|
| Yield prediction | Post-hoc SPC alerts when yield drops below control limit | Answers 'will this batch meet yield target?' when asked | Continuously forecasts batch outcome from in-process data; triggers intervention before failure |
| Root cause analysis | Manual investigation across 3-5 systems; 5-15 day cycle | Suggests possible causes from the data it can access | Autonomously traces yield deviation across process, material, environmental, and equipment variables |
| Parameter optimization | Operators adjust based on experience and SOPs | Recommends adjustments when prompted | Identifies optimal parameter windows from cross-batch analysis; recommends within validated ranges |
| Cross-batch learning | Tribal knowledge; lost when operators rotate | Searches historical data when asked specific questions | Builds persistent memory across every batch; detects emerging patterns before they become deviations |
Skill 1: Yield Prediction
The yield prediction skill operates during batch execution. As in-process parameters stream in — granulation torque curves, blend uniformity samples, compression force profiles, coating weight gain measurements — the agent compares the evolving pattern against its learned models from hundreds of previous batches of the same product.
When the agent detects a trajectory that historically correlates with sub-target yield, it doesn’t wait for the batch to complete. It generates a prediction with a confidence interval, identifies which parameters are deviating from the optimal envelope, and escalates with a specific, actionable recommendation — not a generic alert.
Skill 2: Root Cause Analysis
When a yield deviation occurs, the root cause analysis skill activates. Unlike a human investigator who starts with a hypothesis and searches for confirming data, the agent systematically evaluates all potential contributing factors in parallel: raw material lot properties (particle size, moisture content, potency from COAs), process parameters (deviations from setpoints across all unit operations), environmental conditions (temperature and humidity trends during processing), and equipment status (calibration dates, maintenance history, cumulative batch count since last service).
The agent cross-references these factors against the deviation patterns it has observed across all historical batches — not just the current product, but structurally similar products that share unit operations or equipment. This cross-product reasoning is something human investigators rarely do, but it frequently surfaces root causes that single-product analysis misses.
Skill 3: Parameter Optimization
The parameter optimization skill identifies the process parameter windows that maximise yield within validated ranges. This is distinct from process control — it doesn’t change setpoints autonomously. Instead, it analyses the relationship between parameter values and yield outcomes across hundreds of batches and recommends the optimal operating point within the validated design space.
For example: a tablet compression process validated at 8-12 kN main compression force may show that batches run at 9.5-10.5 kN consistently achieve 1.2% higher yield than those at the specification boundaries. The agent identifies this optimal window, recommends it to operators, and monitors whether the recommendation is followed and whether the predicted improvement materialises.
Skill 4: Cross-Batch Learning
The cross-batch learning skill is what makes agentic yield intelligence compound over time. Every batch — whether it meets target yield or deviates — adds to the agent’s institutional memory. This memory is structured, not raw: the agent doesn’t simply store batch records, it extracts yield-relevant patterns, correlations, and causal relationships.
After 500 batches, the agent knows that Product A’s yield is sensitive to API particle size distribution in the D90 range, that Granulator 3 produces marginally lower yield than Granulators 1 and 2 (suggesting a maintenance issue), and that yield drops by 0.8% on average when relative humidity exceeds 55% during compression. This knowledge persists across operator shifts, site transfers, and personnel changes.
The Integration Architecture: Three Data Domains
What an agentic yield system needs to reason across
An agent is only as capable as the data it can access. The critical differentiator of agentic yield intelligence is not the AI model — it’s the integration architecture that gives the agent real-time access to six data streams — grouped into three integration domains — required for cross-system reasoning.
Most facilities have these systems. Almost none connect them in a way that supports real-time, autonomous reasoning.
Process Execution
MES batch records (in-process parameters, operator actions, batch genealogy) combined with process historian time-series data at sub-second resolution (temperatures, pressures, torque curves, RPMs). Together they give the agent both the structured batch context and the high-frequency sensor patterns needed for real-time yield prediction.
Quality & Analytical
LIMS results (blend uniformity, dissolution, content uniformity, moisture) correlated with environmental monitoring data (cleanroom temperature, relative humidity, differential pressure, particle counts). The agent links analytical outcomes to environmental conditions — surfacing subtle yield impacts that manual investigations miss.
Materials & Equipment
Raw material COAs (particle size, moisture, potency), supplier lot tracking, and material property trends — combined with equipment maintenance logs, calibration records, and OEE patterns. The agent correlates material variability and equipment drift with yield outcomes: the two most commonly missed root causes in manual investigations.
The integration architecture must support both read access (the agent querying current and historical data) and write access (the agent logging its observations, predictions, and recommendations back into the MES as auditable entries). This bidirectional integration is what keeps the agent within GMP compliance — every reasoning step and recommendation is captured in the audit trail, attributable, and reviewable.
Real Scenarios: Granulation, Compression, Coating
How agentic yield intelligence works in practice
Abstract architecture becomes concrete when applied to the three unit operations where solid oral dosage manufacturers lose the most yield.
Granulation endpoint
Operator monitors torque/power curves visually; endpoint called based on experience. Over-granulation wastes 2-5% yield; under-granulation causes downstream failures.
Detected post-batch
Agent compares real-time torque profile against optimal endpoint models from 300+ previous batches, factoring in current API lot moisture content from COA. Flags optimal endpoint 30-60 seconds before operator would typically call it.
Predicted in real-time
Compression force drift
Weight variation and hardness checked at intervals. Compression force adjusted reactively when tablets fail in-process checks. Reject rate: 1-3% of tablets per batch.
Corrected after rejects
Agent monitors per-tablet force profiles, detects drift patterns that precede reject spikes (typically 10-15 minutes before IPC failure), and recommends force adjustment within validated range. Learns which granulation batches require different force profiles.
Intervenes before rejects
Coating weight gain
Coating weight gain monitored by periodic tablet sampling. Over-coating wastes expensive coating suspension; under-coating fails dissolution specifications. Yield impact: 1-4%.
Sampled periodically
Agent correlates spray rate, inlet temperature, pan speed, and tablet bed temperature against weight gain trajectory. Predicts coating endpoint from real-time data, factoring in tablet core properties from upstream granulation and compression data.
Continuously predicted
Deployment Evidence
What agentic manufacturing intelligence delivers in practice
The architecture described in this whitepaper is not theoretical. Organisations deploying AI-native manufacturing execution systems with integrated process intelligence are already measuring impact across multiple dimensions.
While full agentic yield intelligence is an emerging capability, the foundational architecture — real-time cross-system data integration, automated batch review, and predictive analytics — is delivering measurable results at scale.
20→1 days
Batch review cycle
Multi-site deployment: batch review reduced from 20 days to 1 day through automated cross-system data correlation
2,700 hours/year
Time recovered
Previously spent on manual data entry, cross-referencing, and investigation — now available for process improvement
60%
Reduction in manual data entries
Automated data capture from process equipment eliminates transcription errors and enables real-time analysis
These results represent the foundational layer — digitised batch records, automated data capture, and cross-system integration. The agentic layer builds on this foundation: once the data flows are established and the batch record is digital, the agent can begin observing, reasoning, and acting across every batch. The yield intelligence capabilities described in this whitepaper are the next step in a deployment that starts with data integration and progresses through prediction to autonomous action.
Implementation Roadmap
From data integration to autonomous yield intelligence
Agentic yield intelligence is not a single deployment — it’s a progression. Organisations that attempt to jump directly to autonomous agents without establishing the data foundation will fail. The roadmap below reflects what works in practice.
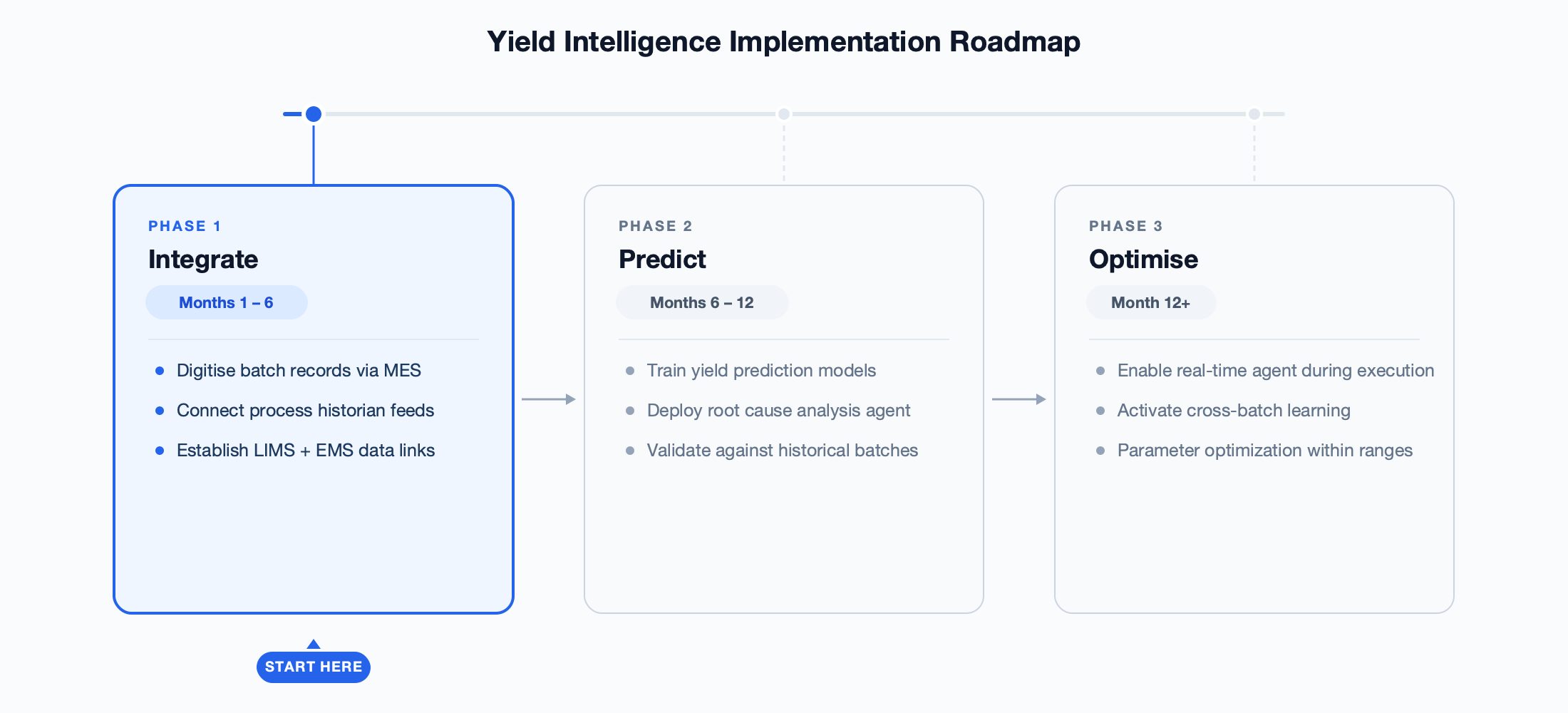
Phase 1: Integrate
Connect the six data streams to a unified digital batch record. Digitise paper-based records, establish real-time feeds from process historians and LIMS, and create the data foundation the agent needs. Without this layer, AI is guessing from incomplete data.
Phase 2: Predict
Deploy yield prediction and root cause analysis skills on historical data. The agent learns yield patterns from hundreds of completed batches before being asked to predict in real time. Validate predictions against actual outcomes; refine models until prediction accuracy exceeds 85%.
Phase 3: Optimise
Enable cross-batch learning and parameter optimization. The agent now operates in real time during batch execution: predicting outcomes, flagging risks, recommending adjustments within validated ranges, and building institutional memory with every batch. Full audit trail maintained for regulatory compliance.
The competitive advantage of agentic yield intelligence compounds. Every batch the agent observes makes it better at predicting the next one. Organisations that start building this institutional memory now will have a structural advantage that late adopters cannot shortcut.
Yield intelligence in pharmaceutical manufacturing is moving from reactive investigation to autonomous prevention. The technology components — real-time data integration, cross-system reasoning, predictive analytics, and goal-based agents — are available today. The regulatory frameworks (ICH Q8-Q10, FDA’s PAT guidance, the emerging Annex 22 AI requirements) explicitly encourage this direction.
The organisations that will capture the most value are those that recognise yield intelligence is not an analytics problem to be solved with better dashboards. It is an architectural problem that requires systems capable of reasoning across every data source, learning from every batch, and acting within GMP guardrails — autonomously, continuously, and with a complete audit trail. The question for manufacturing leadership is not whether this transition will happen, but whether your facility will be the one setting the benchmark or the one trying to catch up.